Machine Learning for Retail Sales Forecasting — Features Engineering
Understand the impacts of additional features related to stock-out, store closing date or cannibalization on a Machine Learning model for sales forecasting
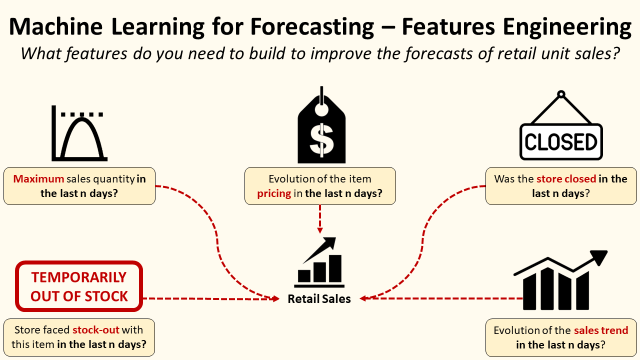
Understand the impacts of additional features related to stock-out, store closing date or cannibalization on a Machine Learning model for sales forecasting
Article originally published on Medium.
Based on the feedback of the last Makridakis Forecasting Competitions, Machine Learning models can reduce the forecasting error by 20% to 60% compared to benchmark statistical models. (M5 Competition)
Their major advantage is the capacity to include external features that heavily impact the variability of your sales.
For example, e-commerce cosmetics sales are driven by special events (promotions) and on how you advertise a reference on the website (first page, second page, …).
This process called features engineering is based on analytical concepts and business insights to understand what could drive your sales.
In this article, we will try to understand the impact of several features on the accuracy of a model using the M5 Forecasting competition dataset.
💌 New articles straight in your inbox for free: Newsletter
I. Introduction
1. Data set
2. Initial Solution using LGBM
3. Features Analysis
II. Experiment
1. Additional features
2. Results
III. Conclusion and next steps
I. Introduction
1. Data set
This analysis will be based on the M5 Forecasting dataset of Walmart stores sales records (Link).
- 1,913 days for the training set and 28 days for the evaluation set
- 10 stores in 3 states (USA)
- 3,049 unique in 10 stores
- 3 main categories and 7 departments (sub-category)
The objective is to predict sales for all products in each store, in the following 28 days right after the available dataset. We have to perform 30,490 forecasts for each day in the prediction horizon.

We’ll use the validation set to measure the performance of our model.
2. Initial Solution using LGBM
As a base model, we will use a very clear and concise notebook shared by Anshul Sharma in Kaggle. (Link)
The idea is to understand how we can improve the accuracy of the model only by adding additional features (without touching the hyperparameters or changing the algorithm).
In this notebook, you will find all the different steps to build a quite good model with a reasonable computing time:
- Import and processing of raw data
- Exploratory Data Analysis
- Features Engineering
i) Seasonality: week number, day, month, day of the week
ii) Pricing: the weekly price of an item in each store, special events
iii) Trends: sales lags (n-p days), average volume per {item, (item +store)}, …
iv) Categorical Variables encoding: item, store, department, category, state - Model Training: 1 model LightGBM per store
3. Features Engineering
In order to emphasize the impact of features engineering, we will not change the model and only look at which features we use.
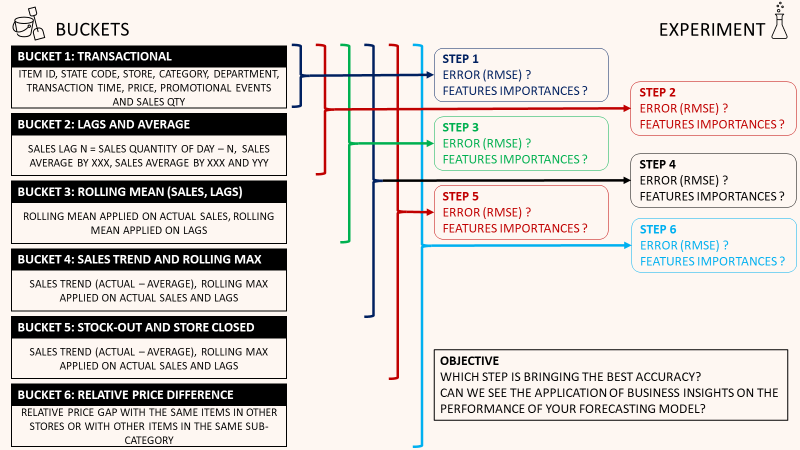
Let us split the features used in this notebook into different buckets.
—
Bucket 1: Transactional Data
'id', 'item_id',
# Store, Category, Department
'dept_id', 'cat_id', 'store_id', 'state_id'
# Transaction time
'd', 'wm_yr_wk', 'weekday', 'wday', 'month', 'year'
# Sales Qty, price and promotional events
'sold', 'event_name_1', 'event_type_1', 'event_name_2', 'event_type_2', 'sell_price'
events and sell_price
Capture the impact on sales of a special event on an item of selling price XXX.
What could be the impact of a special event with -20% reduction on sales of baby formula the second week of the month?
Open Question
What would be the impact on the accuracy if we do one-hot encoding for the categorical features?
—
Bucket 2: Sales Lags and Average
'sold_lag_1', 'sold_lag_2', 'sold_lag_3', 'sold_lag_7', 'sold_lag_14', 'sold_lag_28'
# Sales average by
'item_sold_avg', 'state_sold_avg',
'store_sold_avg', 'cat_sold_avg', 'dept_sold_avg',
# Sales by XXX and YYYY
'cat_dept_sold_avg', 'store_item_sold_avg', 'cat_item_sold_avg',
'dept_item_sold_avg', 'state_store_sold_avg',
'state_store_cat_sold_avg', 'store_cat_dept_sold_avg'
lags
Measure the week-on-week or month-on-month (7 days, 28 days) similarities to capture the periodicity of sales due to people shopping at these frequencies.
Do you have relatives going to the hypermarket every Saturday to shop for the whole week?
II. Experiment
1. Additional features
Based on business insights or common sense, we will add additional features, built with existing ones, to help our model to capture all the key factors impacting your customer demand.
—
Bucket 3: Rolling Mean and Rolling Mean applied on lag
'rolling_sold_mean', 'rolling_sold_mean_3', 'rolling_sold_mean_7',
'rolling_sold_mean_14', 'rolling_sold_mean_21', 'rolling_sold_mean_28'
# Rolling mean on lag sales
'rolling_lag_7_win_7', 'rolling_lag_7_win_28', 'rolling_lag_28_win_7', 'rolling_lag_28_win_28'
rolling_sold_mean_n
Measure the average sales of the last n days.
Rolling mean is sometimes used alone as a benchmark model for statistical forecasting.
Code
rolling_lag_n_win_p
Measure the average sales of a p days windows ending n days ago.
Code
BUSINESS INSIGHTS
Sunglasses seasonality
If the rolling mean of the last 7 days is 35% higher than the average sales of the week before that means you have started the summer season.
—
Bucket 4: Sales Trend and Rolling Maximum
'selling_trend', 'item_selling_trend',
# Rolling max
'rolling_sold_max', 'rolling_sold_max_1', 'rolling_sold_max_2', 'rolling_sold_max_7', 'rolling_sold_max_14', 'rolling_sold_max_21',
'rolling_sold_max_28'
Selling trend
Measure the gap between the daily sales and the average.
Code
Rolling max
What is the maximum sales in the last the n days?
Code
Spoiler: this feature will have an important impact on your accuracy.
—
Bucket 5: Stock-Out and Store Closed
'stock_out_id'
# Store closed
'store_closed'
stock-out
Explain that you have zero sales because of stock availability issues.
Code
—
Bucket 6: Price Relative with the same item in other stores or other items in the sub-category
'delta_price_all_rel'
# Relative delta price with the previous week
'delta_price_weekn-1'
# Relative delta price with the other items of the sub-category
'delta_price_cat_rel'
delta_price_weekn-1
Capture the price evolution week by week.
BUSINESS INSIGHTS
Promotions for Slow Movers
In order to reduce their inventory and purge slow movers, stores may apply aggressive pricing to boost sales.
delta_price_all_rel: Sales Cannibalization at store level
Several stores competing for sales of the same item because of price difference.
delta_price_cat_rel: Sales Cannibalization at sub-category level
Several items of the same sub-category competing for sales.
Code
2. Results
After running a loop of training with the six different buckets (using the same hyperparameter with the Kaggle notebook) we have the following results:
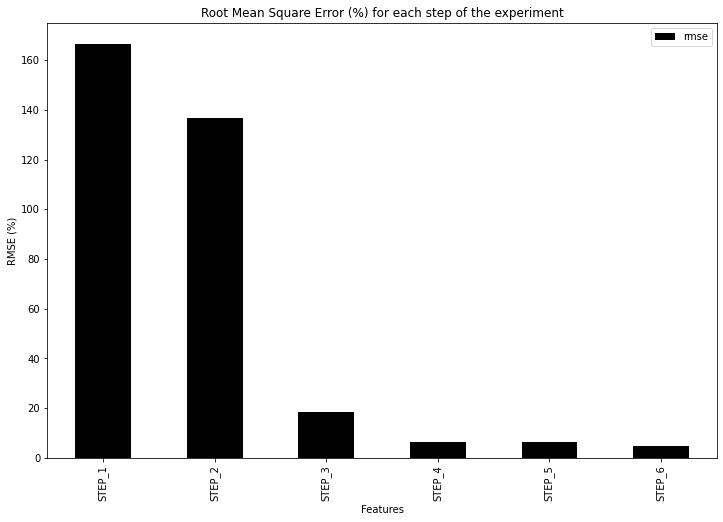
—
STEP 1 to STEP 2: -29% RMSE Error

Sales lags are positively impacting the accuracy of your model:
BUSINESS INSIGHTS
Your sales today are highly impacted by the sales of the previous days.
—
STEP 2 to STEP 3: -118% RMSE Error
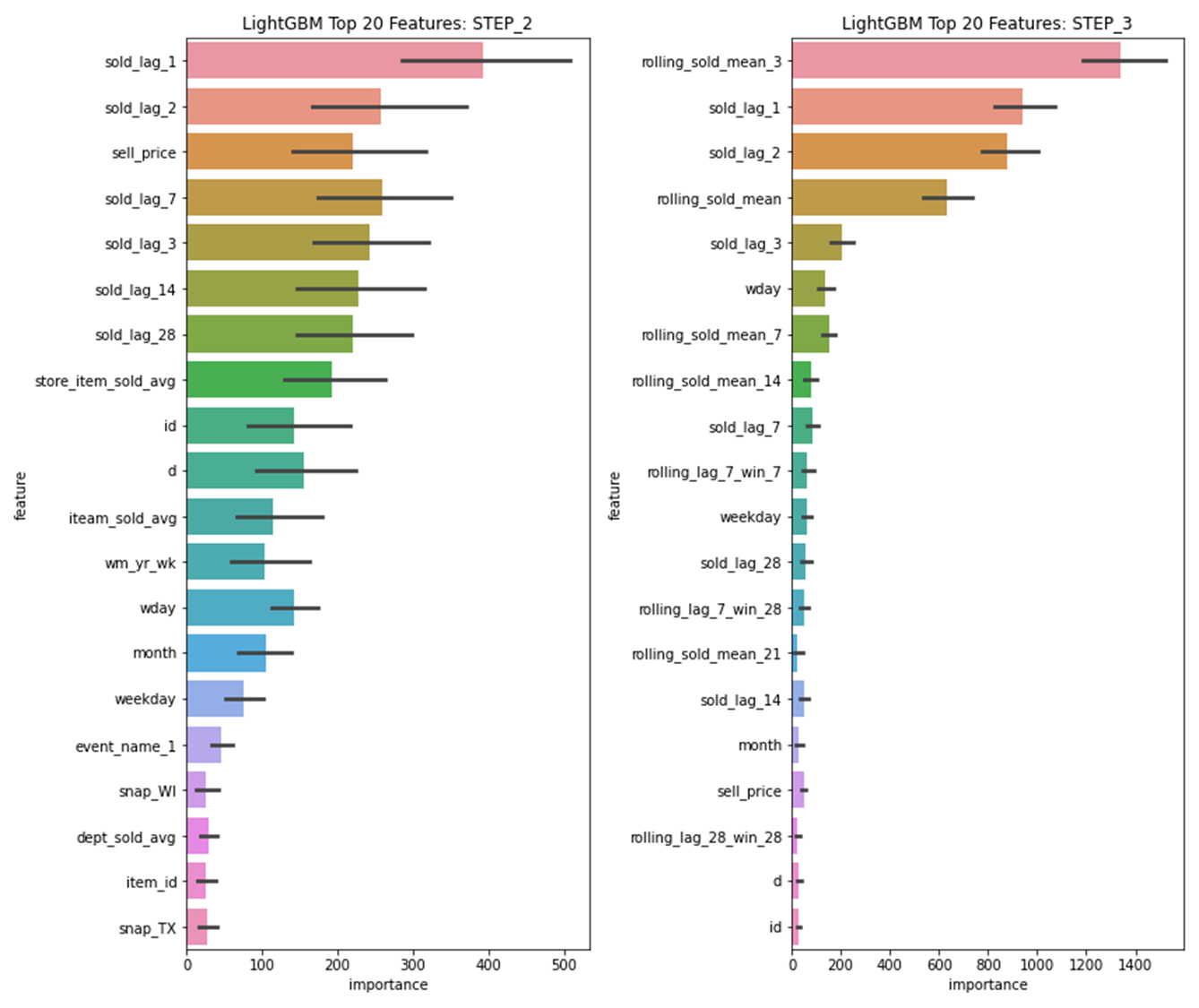
BUSINESS INSIGHTS
The top 3 features are all related to the sales of the last three days.
Question
Based on this insight, what could be the performance of a model like Exponential Smoothing who is taking a ponderate sum of the previous sales to compute the forecasts.
—
STEP 3 to STEP 4: -12% RMSE Error

Rolling max features are taking the lead at the top of the features.
—
STEP 4 to STEP 5: -0.1% RMSE Error

BAM!
I am devastated to see that the potential main added value of this article, showing the impact of stock-out or store closing, has a limited impact on the accuracy of the model.
—
STEP 5 to STEP 6: -1.75% RMSE Error

The model accuracy is slightly better but we do not see any of the added features in the top 20.

III. Conclusion and next steps
Understand the results
The results in terms of model accuracy are quite satisfying.
However, there is still some frustration with not having found any correlation between some of the newly added features and the model performance.
Therefore, the next step will be to work on these features and the model (let’s remember that we did not touch the initial model here) to check if there is any possibility to use these features to better forecast your sales.
If these business insights are not improving your forecasts we need to understand why.
Implement Inventory Management Rules
Now that you have your forecasting model, you need to implement an inventory management rule to manage the replenishment of your stores.
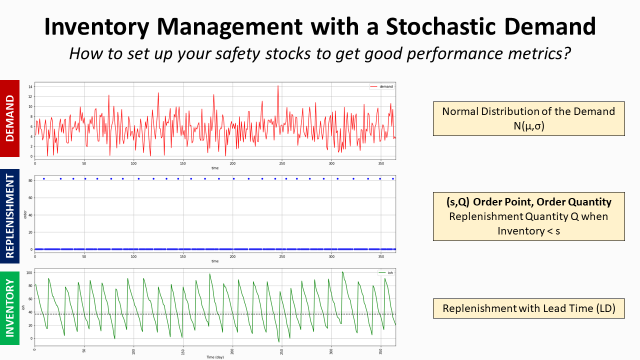
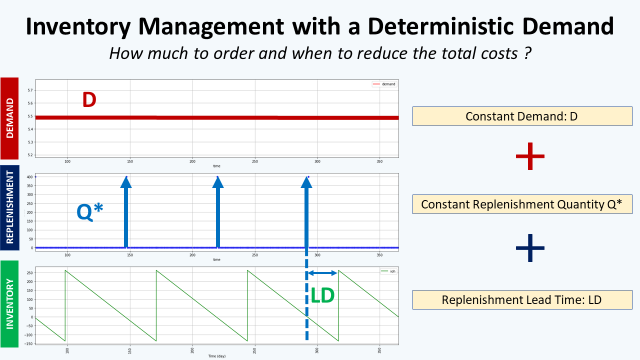
You can take inspiration from these two articles where we try to implement rules assuming a deterministic or stochastic demand.
About Me
Let’s connect on Linkedin and Twitter, I am a Supply Chain Engineer that is using data analytics to improve logistics operations and reduce costs.
References
[1] Time Series Forecasting-EDA, FE & Modelling📈, Anshul Sharma, Link